
关于maxmemory-policy
Redis还提供了一个配置参数 —— maxmemory,该参数是用来配置内存大小的。一旦Redis所使用的内存超过了该参数,就会启动 maxmemory-policy 中所配置的策略。
这里需要说明的是,对于64位的操作系统,maxmemory 参数的默认值为0,表示没有内存大小限制;而对于32位的操作系统,maxmemory 参数的默认值为3GB。
举个例子:
maxmemory 6gb
maxmemory-policy allkeys-lru 或者 volatile-lru

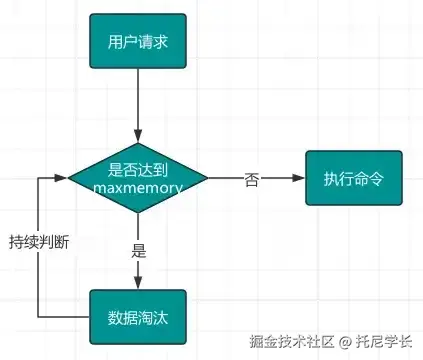
noeviction(默认) :当Redis所使用的内存达到了maxmemory的时候,就不再提供除了del、hdel、unlink以外的其他写操作,但读操作可以继续进行。
volatile-lru:通过近似LRU(最近最少使用)算法来淘汰Redis中的key,淘汰范围是Redis中设置过期时间的key。
volatile-lfu:通过LFU(最不常用)算法来淘汰Redis中的key,淘汰范围是Redis中设置过期时间的key。
volatile-ttl: 淘汰Redis中剩余生存时间最短的key,淘汰范围是Redis中设置过期时间的key。
volatile-random:以随机的方式淘汰Redis中的key,淘汰范围是 Redis中设置过期时间的key。
allkeys-lru:通过近似LRU(最近最少使用)算法来淘汰Redis中的key,淘汰范围是Redis中的所有key。
allkeys-lfu:通过LFU(最不常用)算法来淘汰Redis中的key,淘汰范围是Redis中的所有key。
allkeys-random:以随机的方式淘汰Redis中的key,淘汰范围是Redis中的所有key。
上述的八种策略中,除了noeviction策略之外,剩下的7种策略都会涉及到淘汰key的操作。
而对于淘汰key的判断和执行,是通过每次的用户请求来进行触发的,步骤如下图所示:
LRU 算法和 LFU算法
可能同学们会觉得LRU和LFU两种算法容易混淆,我在这里解释一下。
如果有一条许久不曾被访问的冷数据,偶然间被访问了一次,如果按照LRU算法的规则,这条数据就会被定义为热数据,短期内不会被淘汰。
但按照LFU算法的规则,这条数据可能仍然是最近一段时间内被访问频率最低的,还是会被淘汰掉的。
LRU关注于“最近是否被访问”,LFU关注于“最近的访问频率如何”,相对而言,后者的实现方式更加合理一些。
近似 LRU 算法
标准的LRU算法,其底层是通过双向链表 + Hash表进行实现的,双向链表可以保证数据的插入和删除操作的时间复杂度为O(1),而Hash表可以实现数据查找的时间复杂度为O(1),将两者的优势结合起来堪称完美。
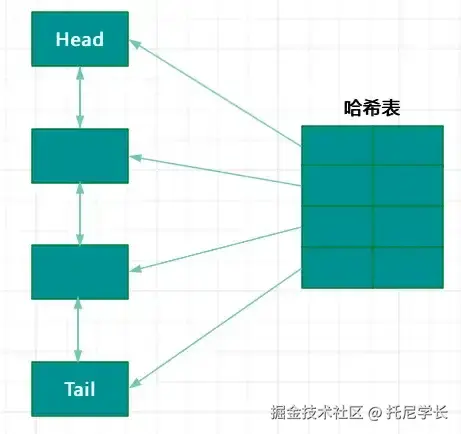
但根据Redis官方文档所述,Redis并没有按照标准的LRU算法进行实现,而是采取了一种“近似LRU”的实现方式。
其原因在于:
(1)Redis内部只实现了Hash表,而标准的LRU算法则需要双向链表 + Hash表两种数据结构。换言之,需要在Redis内存中再额外增加一个双向链表,这个内存消耗的代价是不可接受的。
(2)每个Redis请求,LRU的双向链表也需要进行同步操作,这种实现方式对性能影响不小。
而Redis本身实现的“近似LRU”算法,则远远不需要付出这么大的内存和性能代价,但也牺牲了一些内存淘汰的准确率。
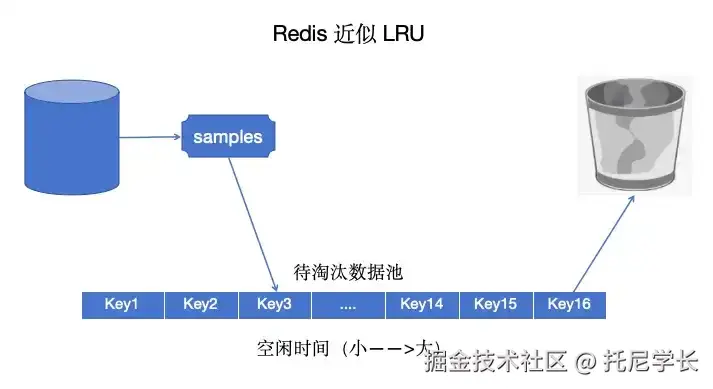
我们来看一下具体的实现方式:
(1)Redis通过引入LRU时钟值的方式,来记录数据每次被访问的时间。
(2)随机挑选出一批数据,将其一一与“按照空闲时间升序排列的”待淘汰数据池中的数据进行比对。
btw:空闲时间 = 当前时钟值 - LRU时钟值,待淘汰数据池的默认大小为16。
- 若待淘汰数据池中已满,且该数据的空闲时间最小,则跳过;
- 若待淘汰数据池中未满,且该数据要写入的位置为空,则执行写入操作;
- 若待淘汰数据池中未满,且该数据要写入的位置不为空,则将目前处于该位置及后面的元素都后移一个位置,再执行写入操作;
- 若待淘汰数据池中已满,则将数据要写入位置前面的元素都前移一个位置,再执行写入操作;
批次数据的数量,是由 maxmemory-samples 参数来决定的,默认值为5。该参数值设置越大,就越能提升内存淘汰的准确率,但也会增加服务器的CPU消耗。
(3)从待淘汰数据池中,淘汰掉空闲时间最大的那条数据,同时会根据Redis中的惰性删除配置,来决定在Redis字典中执行同步删除还是异步删除。
(4)此时若释放的内存空间未能小于 maxmemory 参数值,则重复执行上述步骤中的(2)(3),直至达成目标为止。