
缓解Token焦虑:在 VS Code Copilot 中集成 NVIDIA 免费模型
如果Github Copilot订阅额度用完了怎么办?加钱 or 找免费平替?
今天推荐的可以长期薅羊毛(目前)的方案是NVIDIA NIM。NVIDIA 提供了强大的 AI 模型服务,上面有大量顶级开源模型给开发者免费调用,让开发者可以零成本体验高性能的 AI 辅助编程。
本文将手把手教你如何通过 OAI Compatible Provider for Copilot 插件,将 NVIDIA 的免费大模型集成到 VS Code Copilot 中。
一、为什么选择 NVIDIA NIM?
在开始之前,先来看看为什么值得折腾 NVIDIA NIM:
| 优势 | 说明 |
|---|---|
| 免费额度 | 没有token数量限制,40 rpm的限速也基本能接受,目前暂未发现有其他限制 |
| 顶级模型 | 提供接近200个免费模型,其中就包括Llama 3.1 405B、Qwen3 Coder 480b等开源界最强模型 |
| 超低延迟 | NVIDIA 自有的推理优化技术,响应速度远超普通 API |
| OpenAI 兼容 | 完美兼容 OpenAI API 标准,可无缝对接各类插件 |
二、准备工作
1. 注册 NVIDIA 账号并获取 API Key
- 访问 NVIDIA BUILD 官网
https://build.nvidia.com - 点击右上角login按钮,输入邮箱(如果邮箱没有注册会跳转到注册页面)注册过程很简单,不需要魔法。
- 进入 API Keys 页面,点击 Generate Key 创建新的 API Key,有效期可以选择永久。
- 重要:妥善保存生成的 Key,格式类似
nvapi-xxxxxxxxxxxxxxxx
2. 安装必要插件
在 VS Code 扩展市场中搜索并安装:
- OAI Compatible Provider for Copilot(必需)
- GitHub Copilot(当然要有)
三、配置 NVIDIA NIM 接入
步骤 1:打开插件设置
- 按
Ctrl + Shift + P(Windows) 或Cmd + Shift + P(macOS) 打开设置 - 搜索
OAICopilot: Open Configuration UI
步骤 2:填写配置参数
先看下示例:
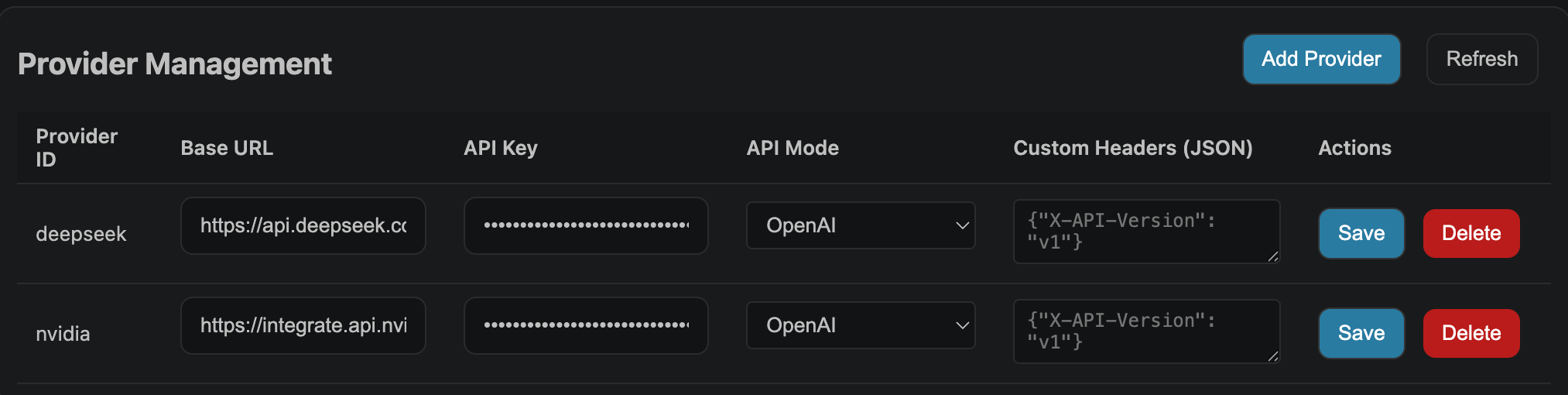
Provider
| 配置项 | 值 | 说明 |
|---|---|---|
| Base URL | https://integrate.api.nvidia.com/v1 |
NVIDIA NIM 的 API 端点 |
| API Key | nvapi-xxxxxxxxxxxxxxxx |
你刚才生成的 Key |
| Provider ID | NIM |
自定义名称,方便识别 |
| API Mode | OpenAI |
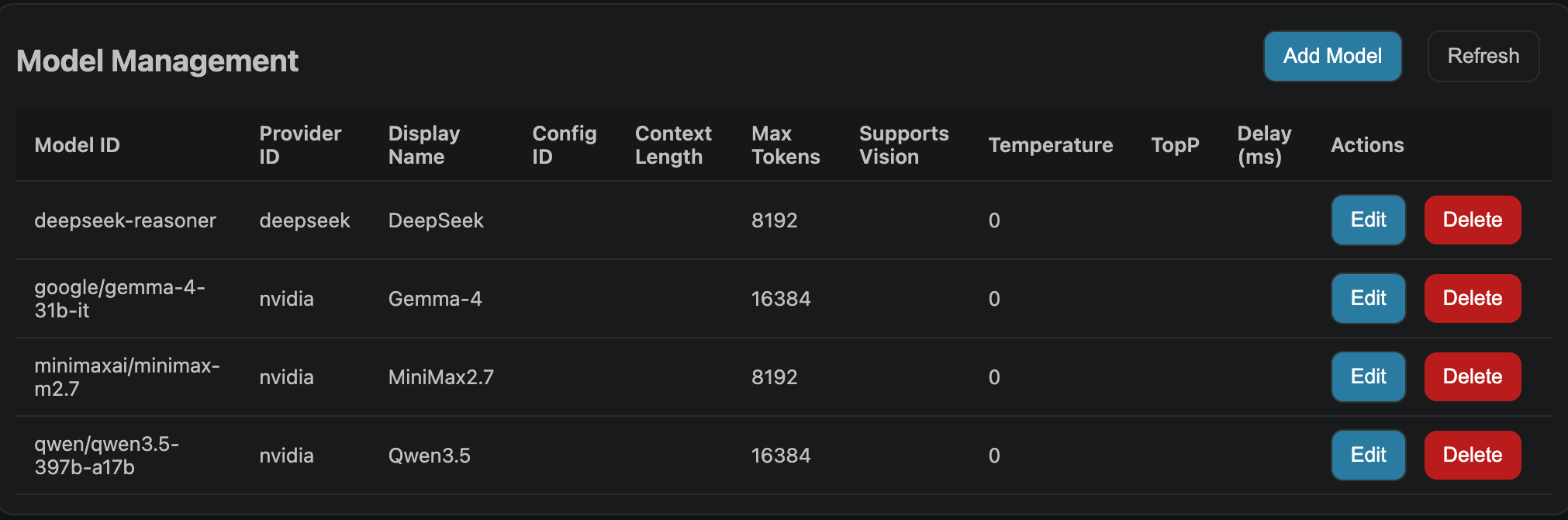
Model
| 配置项 | 值 | 说明 |
|---|---|---|
| Model ID | qwen/qwen3-coder-480b-a35b-instruct |
从NIM页面复制,不要填错 |
| Provider ID | NIM |
填写 Provider 里面配置的值 |
| Display Name | Qwen3 Coder |
模型显示的名字 |
推荐模型列表:
-
meta/llama-3.1-405b-instructMeta Llama 3.1 多语言大型语言模型(LLM)系列是一组预训练且经过指令微调的生成式模型,包含 8B、70B 和 405B 三种规模(文本输入/文本输出)。Llama 3.1 指令微调文本专用模型(8B、70B、405B)针对多语言对话场景进行了优化,在常见的行业基准测试中表现优于许多现有的开源和闭源聊天模型。
-
qwen/qwen3-coder-480b-a35b-instruct一款专为代码生成和代理式编码任务设计的尖端大型语言模型。它是一种专家混合(MoE)模型,总参数数达 4800 亿,激活参数数为 350 亿,原生支持 262,144 个令牌的上下文长度,并可通过 YaRN 扩展至 100 万个令牌。
-
minimaxai/minimax-m2.7MiniMax M2.7 是一款专为复杂软件工程、智能工具使用及办公生产力工作流设计的大型语言模型。该模型被设计为深度参与自身进化的系统,支持复杂的智能体框架、动态工具搜索、智能体团队协作,以及高保真度的编码和文档编辑任务。
-
google/gemma-4-31b-it由 Google DeepMind 构建的开源多模态模型,可处理文本和图像输入,将视频作为帧序列进行处理,并生成文本输出。该模型旨在利用消费级 GPU 和工作站,在推理、代理工作流、编码以及多模态理解方面提供前沿水平的性能,其上下文窗口为 256K 令牌,并支持 140 多种语言。
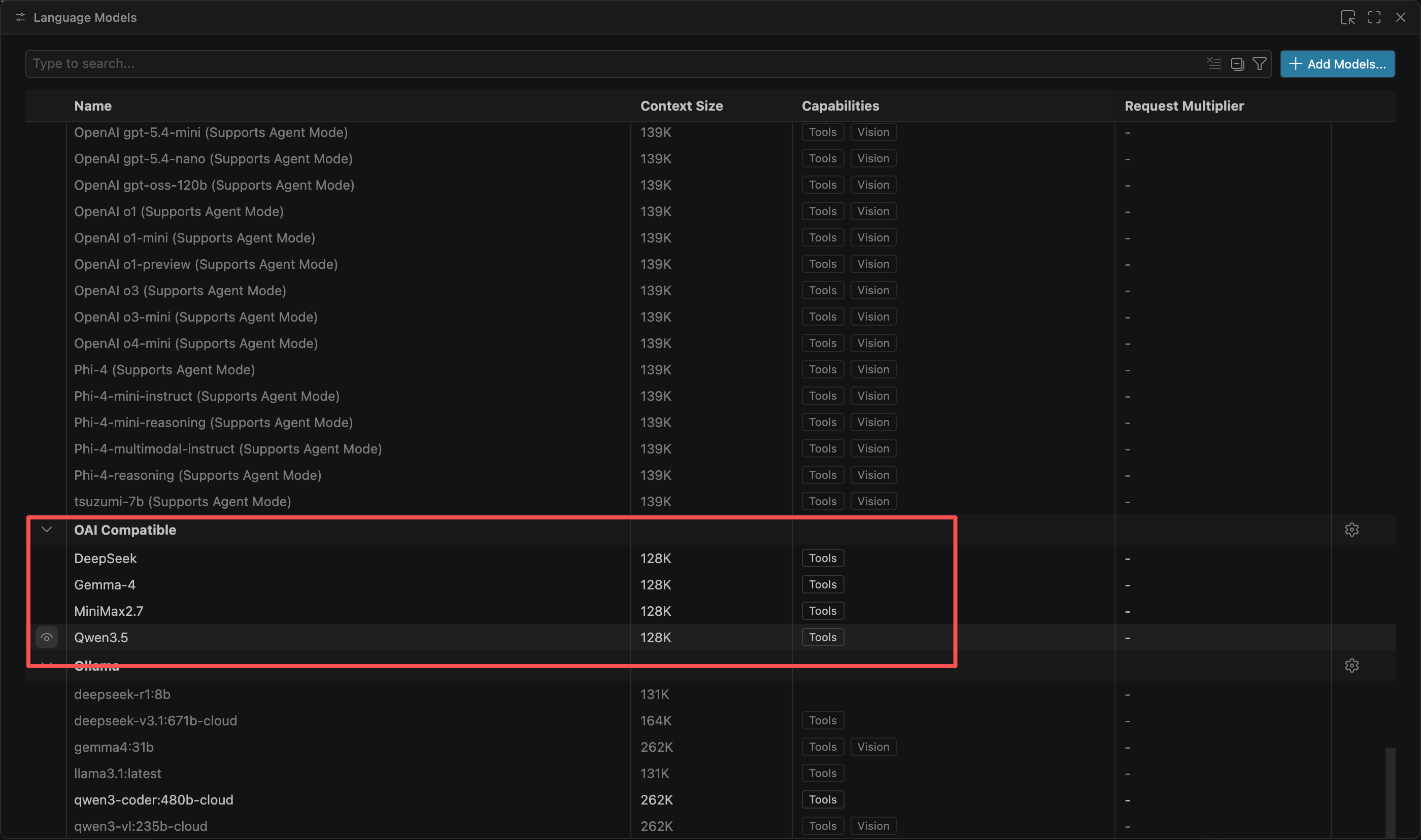
三、切换模型
在 Copilot Chat 窗口的模型选择下拉菜单中,点击配置按钮,等待弹出窗口加载完模型列表,找到OAI Compatible部分,定位到相应模型位置,点击模型前面的图标,使其显示在模型选择列表中。
四、验证与使用
1. 切换模型
- 打开 Copilot Chat 窗口
- 在聊天窗口顶部,点击模型选择下拉菜单
- 选择刚才配置的模型名称
2. 测试连接
在聊天窗口输入:
请确认你的模型版本和提供商
如果返回类似以下信息,说明配置成功:
我是 Llama 3.1 405B,由 NVIDIA NIM 提供推理服务...
3. 实际使用场景
代码补全:
# 输入注释,让 NVIDIA 模型帮你补全
def quick_sort(arr):
# 使用分治法实现快速排序
...
代码解释:
选中一段复杂代码,在 Chat 中输入:@selected 请用中文解释这段代码的逻辑
重构建议:
@file:src/app.py 请分析这个文件的代码结构,并提出重构建议
五、常见问题排查
问题 1:提示 "401 Unauthorized"
原因:API Key 无效或已过期
解决:重新生成 Key 并检查是否复制完整(包含 nvapi- 前缀)
问题 2:响应超时
原因:网络连接问题
解决:
- 检查 VS Code 代理设置(
Http: Proxy) - 尝试更换模型(70B 比 405B 响应更快)
- 检查 NVIDIA 服务状态:https://status.nvidia.com/
问题 3:模型列表中没有显示
原因:模型被隐藏
解决:
- 打开Copilot模型列表
- 定位到相关模型位置
- 检查模型前面的图标状态,如果是隐藏状态,点一下图标切换到显示
- 关闭弹窗后再次点击Chat窗口的模型选择下拉框,展开Other Models检查模型是否显示
问题 4:提示 "429 Too Many Request"
原因:请求过多出发限流
解决
- 检查是否有多个应用同时使用(有此需求的可以试一下使用不同的账号,注意不是API Key)
- 间隔一段时间再试
- 打开OAICopilot的配置面板,找到Delay输入框,输入请求间隔时间(毫秒),建议2000以上。
六、与其他方案的对比
| 方案 | 成本 | 模型能力 | 响应速度 | 隐私性 |
|---|---|---|---|---|
| NVIDIA NIM | 免费 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 中 |
| Ollama 本地 | 免费 | ⭐⭐⭐ | ⭐ | 高 |
| DeepSeek | 低价 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 中 |
| GPT-4 | 高价 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 低 |
推荐策略:
- 日常开发:使用 Ollama 本地模型(零成本,但前提是电脑能跑起来)。
Ollama提供了一些免费额度,不过量很少,一周的免费额度不到一个上午就能干没了,对于依赖于AI进行开发的朋友来说约等于没有。
- 复杂任务:切换到 NVIDIA NIM(薅免费羊毛)
- 关键项目:考虑付费订阅 GPT-4 或 Claude
总结
通过 OAI Compatible Provider for Copilot 插件,我们可以轻松将 NVIDIA 的免费大模型集成到 VS Code 中,享受顶级 AI 辅助编程体验的同时,还能"薅"到 NVIDIA 的免费羊毛。至于这羊毛能薅多久我心里也没底,能用一天是一天吧,都免费了,还要啥自行车?
参考链接
- NVIDIA NIM 官网
https://build.nvidia.com - OAI Compatible Provider for Copilot 插件
https://marketplace.visualstudio.com/items?itemName=johnny-zhao.oai-compatible-copilot - Llama 3.1 模型文档
https://llama.meta.com/llama3