
数据埋点是一种常用的数据采集方法,方便产品/运营系统性的统计分析复杂的用户数据。我们在App端所设置的自定义事件,就是通过数据埋点的方式,实现对用户行为的追踪,以及记录行为发生的具体细节。在网站日益成熟后,管理者可通过统计分析数据来获取网站使用情况。如何全面、完整地统计网站的访问情况和运行情况需要产品经理结合业务进行深层次的思考。

一、前置工作
1. 全面记录系统日志
日志记录的完整性决定了后续统计的数据来源。日志记录一般需要记录用户的操作、业务线、访问模块、操作说明、操作时间、响应时间、数据来源、异常说明等信息。
其中,访问UA又可进一步解析,从中提取出使用的操作系统、浏览器和设备型号,便于后续更好地维护。
日志记录不仅仅从用户的操作层面去记录,更要从业务线的角度进行记录,在涉及到业务的统计时仅靠操作日志是难以出结果的,具体的业务线需要产品经理进行定义。
比如用户提交一个事件,以事件为单位,记录该事件的提交时间,审核时间、处理时间、办结时间、反馈时间等。记录全流程的过程,可统计办结率、平均办理时间等,这就是从业务的角度去记录。
2. 日志存储和读取方式
日志的数据量大,通常以TB为单位,那么如何存储这么大的数据量,如何在大数据中读取数据并解析是需要提前考虑的问题。
目前市面上主流的处理方式是使用Hadoop进行处理。
3. 日志解析和清洗
日志一般获取到的形式为一长串的字符。需要从中提取出有效信息,才能方便后续的统计。所以要将UA解析为结构化的日志模板和参数。
比如UA为Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0 ,可以解析出浏览器、渲染引擎、操作系统、设备型号和CPU信息。

同样的,访问失败日志也需要从报错信息中解析出相关的信息。
数据清洗是将数据中一些脏数据、缺失数据进行处理。具体包括去除重复数据、填补缺失值、处理异常值和转换数据格式等操作,是为了提高后续统计的准确性和可靠性。也是数据预处理中重要的一环。
4. 日志应用
日志的记录目的在于运维和系统分析。
一方面是对运维来说,能够快速定位到用户操作,通过对用户操作的日志分析,可以得出操作失败的原因。或模拟用户的访问环境进行模拟登录,还原用户访问失败的场景。
另一方面,可用于系统分析,统计不同时间段的访问量、访问人数、不同应用的访问量和人数、较同期、上期的对比数据等。从统计的数据中得出某些结论从而反哺于系统是我们的终极目的。比如根据用户的使用系统时间段高峰期可以预测用户的集中使用系统时间,在该时间段内加强系统监控,提高其稳定性高,减少系统更新,都有助于优化用户的使用感受,提高口碑。
还可以根据系统的访问情况得出最好用的某业务以及最难用的业务,取长补短,进行分析改进。根据用户的访问习惯对用户进行画像分析,得出用户感兴趣的某些领域,并推荐相关联的信息。
从日志信息中能挖掘的的信息很多,具体要看产品经理如何去分析,最好是有大数据相关背景的人士进行指导和讨论,结合具体的业务,才能最大程度地发挥日志的作用。下面会展开讲具体的统计维度和分析角度。
二、系统统计
1. 统计概况
常见的统计包括浏览量、独立访客、IP、访客次数、新独立访客数、平均访问时长、人均浏览页数、平均访问深度,跳出率,以下是上述统计项的具体定义和算法,用户可根据自己的系统和统计项进行取舍。同时要确定统计的时间维度,一般来说,会有四个统计维度,按日,按周,按月,按年,且统计时间一般截止到昨天的24:00,今日的数据要明日才能统计出来。以下是一些常见的统计项的定义和算法。

1)浏览量/浏览次数(PV)
即通常说的PV(PageView)值,选定时间段内访客访问应用的页面总次数。访客每打开一个页面被记录一次,同一页面打开多次浏览量值累计计算。
2)独立访客(UV)
即通常说的UV(Unique visitor)值,一天之内访问应用的独立访客数(以Cookie或设备ID为依据),一天内同一访客多次访问应用只计算为一个访客。选定时间段内的访客数为时间段内的每一天访问应用的独立访客数的累计值。
3)IP
一天之内访问应用的独立IP数,一天内同一IP多次访问应用只计算为一个IP。选定时间段内的IP数为时间段内的每一天访问应用的独立IP数的累计值。
4)访问次数
选定时间段内访客访问应用的总次数。访客首次访问或距离上次访问超过30分钟再次访问会被记录为一个新的访问。
5)新独立访客
当日的独立访客中,历史上首次访问网站的访客为新独立访客。
6)平均访问时长
选定时间段内访客访问应用的平均时长。
访客的单次访问中,访问的总时长为打开第一个页面到退出或关闭最后一个页面的时间差。
平均访问时长=访问总时长 / 访问次数
7)人均浏览页数
平均每个独立访客产生的PV。体现网站对访客的吸引程度。
人均浏览页数=浏览次数/独立访客
8)平均访问深度
平均每次访问(会话)产生的PV。体现网站对访客的吸引程度。
平均访问深度=浏览次数/访问次数
9)跳出率
只浏览一个页面就离开或关闭应用的访问次数占总访问次数的百分比。
跳出率=跳出次数 / 总访问次数 * 100%
除了统计上述的数据项之外,还可以进行同期数据的对比,使得数据项的变化更直观。如果要显示今日的数据,则刷新功能必不可少,因为日志的统计是实时的,在页面加载完成后还会有数据的更新。
2. 应用统计
日常的统计按应用角度来。范围广到细可根据:按应用,按模块、按内容三级来统计。应用统计是比较笼统的统计,看的是整体的数据,这个应用的整体趋势和使用情况。统计项可以包括PV、UV、IP、访问时长以及一些同比环比数据等。并且可以统计一些常见的业务数据。
某一应用再按功能可细分为二级模块、三级模块…按需再往下统计具体二三级模块的访问数据。
模块下某些上新的新功能也可做埋点,统计使用情况。比如上新了智能查重功能,就可以统计上线以来的使用次数,最后用该功能提交的文章,从而统计使用率。
按内容统计是最细分的一个统计。这个需要涉及到业务的分析。比如一个讨论群中的人数、发言帖子数。一篇文章的点击量、浏览量、点赞数和收藏数。这些都是精确到某一具体内容。
统计可根据不同的数据进行升序降序排序,统计的时间维度也是按日、按周、按月、按年。
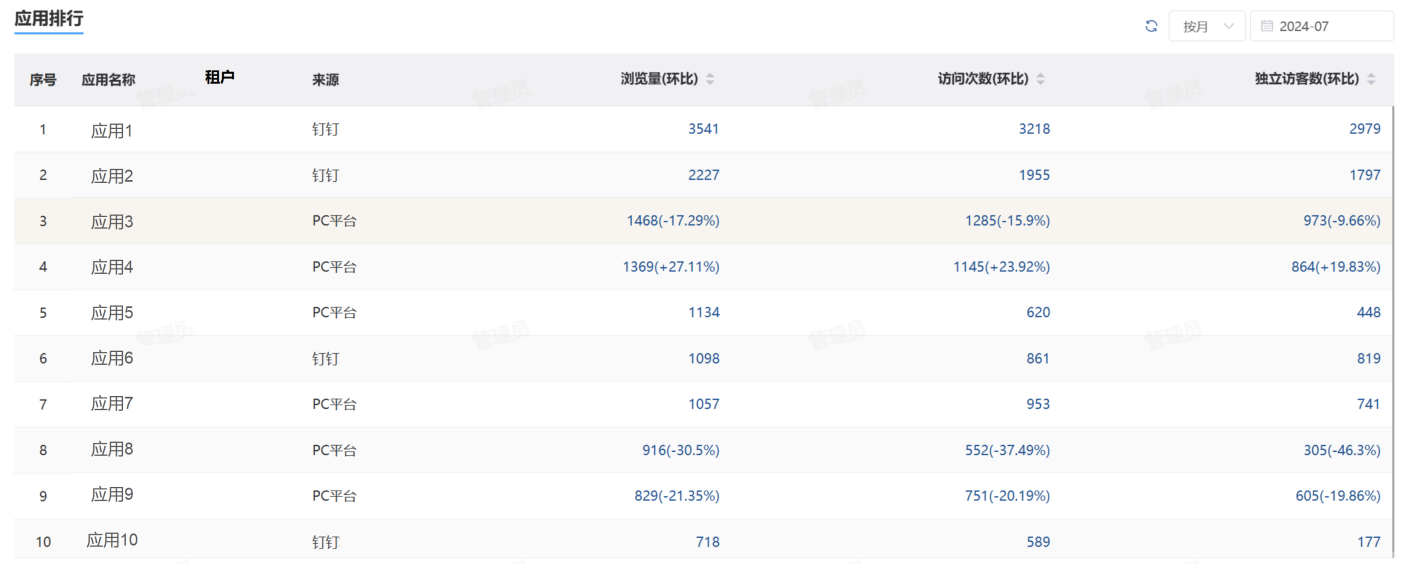
3. 按租户统计
SaaS系统会有多个租户,系统的内容包括统建应用和个性化应用。那么可以根据这两个方面去进行统计。
统建应用统计不同租户下应用的访问量、访问人数,同比数据,然后一些应用的业务数据,比如提交文章数,发布帖子数、讨论数等。从中可看出哪个租户的使用情况最活跃。对使用不活跃的租户进行回访,了解具体情况。
个性化应用需提前定义好需要统计的内容,同样也是统计应用的访问量、访问人数,访问IP数、新用户数、平均访问时长,同比数据和一些应用的业务数据。具体的统计项从上文的【常见的统计项】中去定义。个性化应用中使用得比较好的应用也可以考虑升级为统建的产品,扩大适用范围。
活跃用户数、留存用户数这两项也是考察系统使用情况的重要指标之一。活跃用户数可根据登录次数来定义,日活、月活的定义具体看系统的使用情况。比如有些系统定义一天登录一次,登陆时间超过30min就为日活跃用户。一个月登录3次,登陆时长超过2h就为月活用户。
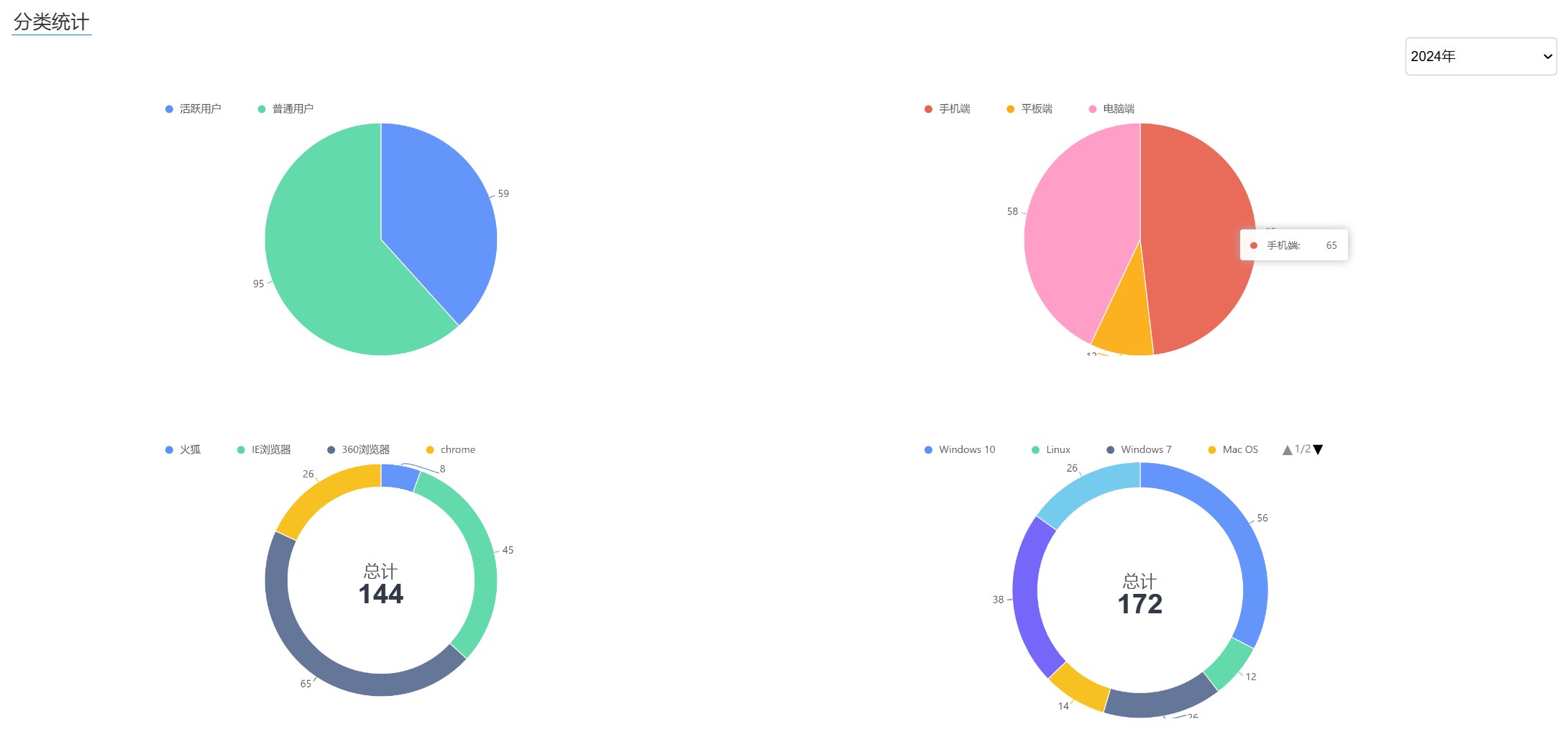
4. 按设备统计
按设备统计主要是统计用户终端类型、操作系统、浏览器、分辨率、访问地区。用户的终端类型包括移动端设备和非移动端设备,操作系统包括Windows7、Windows10、Windows11、Linux、Mac OS…,浏览器包括360、火狐、谷歌、Safari、搜狗…,分辨率包括19201080、1600900、1536*864…访问IP地区包括北京市、上海市、河南省、河北省…。统计这些维度主要是为了了解用户的使用习惯,把系统做得更适配。
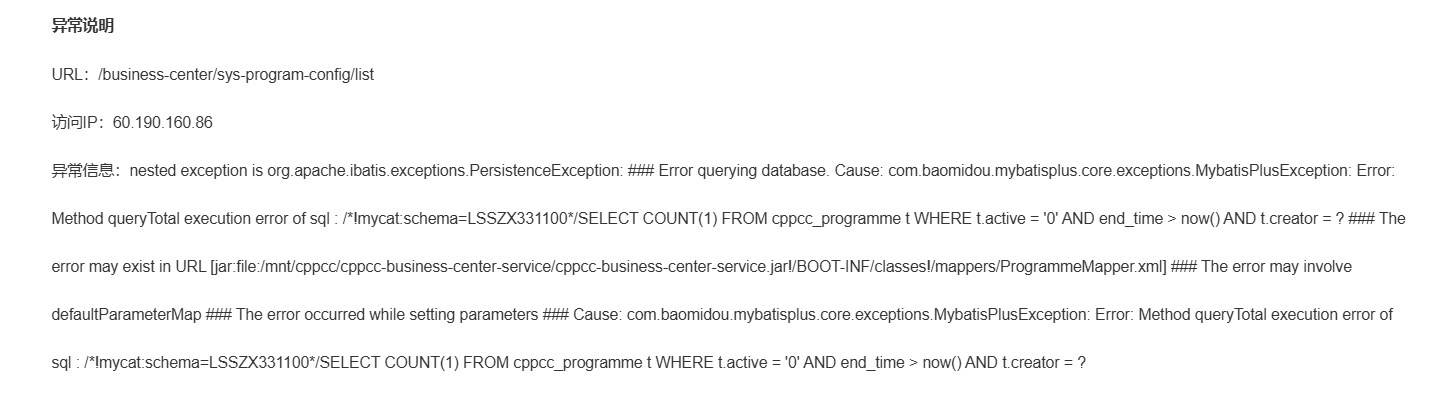
5. 异常数据统计
异常数据主要涉及到上网异常情况、访问失败日志、系统漏洞攻击、报警通知四方面。上网异常情况包括流量激增、用户激增、某一功能点击数激增,在监测到异常访问请款时要根据实际情况来进行分析。
访问失败日志主要包括访问的用户、失败的业务模块、功能、访问失败的原因、报错返回的信息等。系统漏洞的和攻击需要进一步根据情况设计。在系统出现上述异常情况时,可设置自动发送短信功能,及时通知负责人员进行问题的排查,减轻危害。
三、数据挖掘与分析
数据的挖掘与分析是日志的最后归口和产出。如何在海量的数据中挖掘出有用的信息,提高产能和效率是最考验产品经理的一件事。
我们都听过啤酒和尿布的故事,20世纪90年代,在美国有婴儿的家庭中,购买尿布的任务往往由年轻的父亲负责,他们会在买尿布时顺带为自己购买啤酒。沃尔玛超市尝试将啤酒与尿布摆放在相同的区域,并通过一次销售两件商品而获得更好的销售收入。对购买信息进行数据分析,得出尿布和啤酒的线性关系,就是一种典型的数据挖掘与分析。
本文只讨论一些简单的分析方法,具体内容还需具体分析。
1. 可视化展示
在文章的第二章节,提到了许多的统计维度,展示的方式不仅仅局限于表格,适合的方式展示会事倍功半。趋势图可以查看系统的使用趋势,根据时间来观察用户使用频率高的时间。
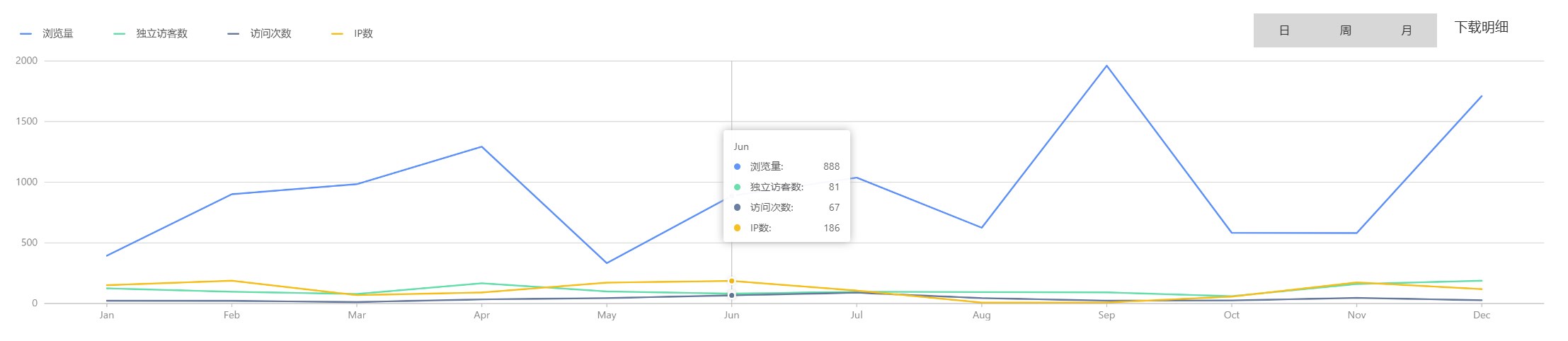
活跃度情况可以用棋盘格来显示,在GitHub中非常常见。

也可用图表结合的方式对统计数据进行展示,统计图是展示分类和趋势,表格展示具体信息,结合起来会效果更好,能反映的数据信息也更多。
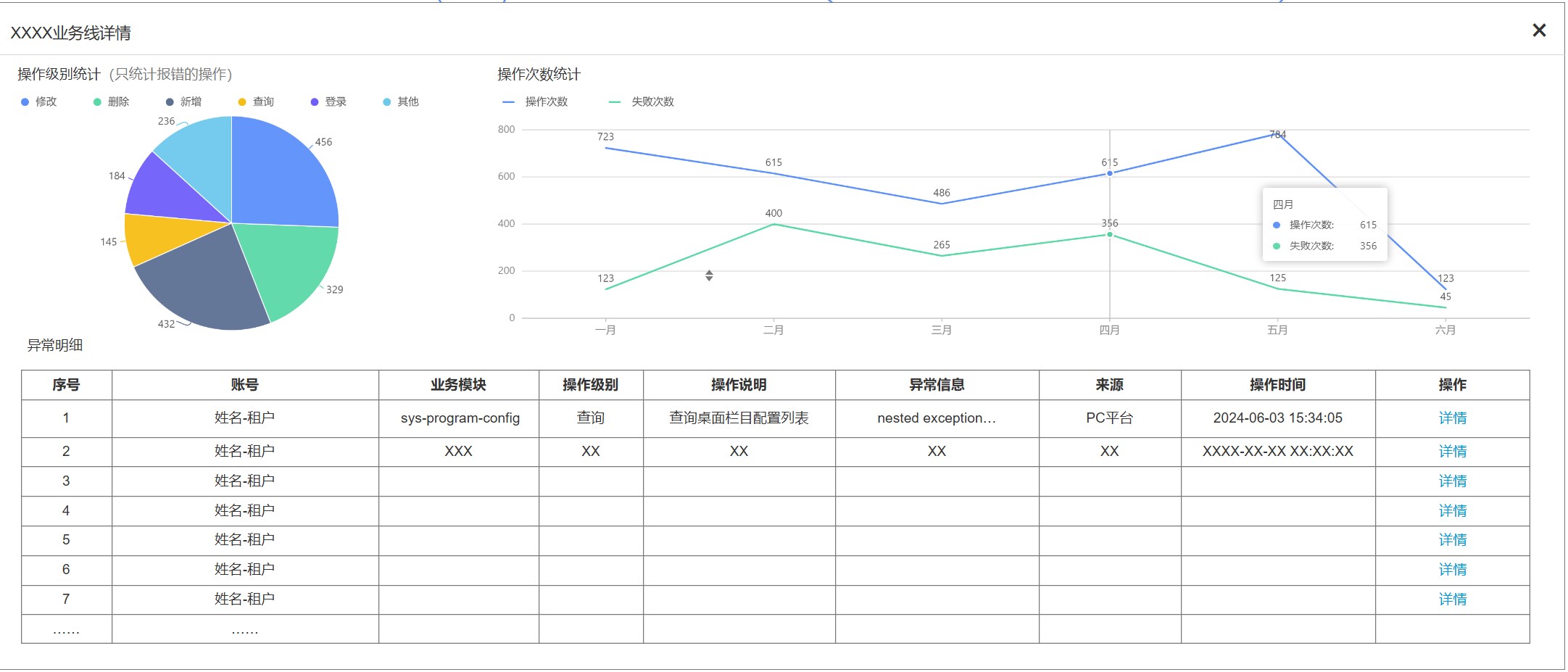
2. 分析反馈,优化系统
系统的分析反馈是渗透在统计中的,这需要产品经理有一双智慧的眼睛。
比如系统的访问日志中,有可能出现访问的周期性,那么根据用户习惯在访问频率高的时候推送一些爆点新闻,可提高用户的留存率和用户粘性。系统的报错日志统计出报错最多的前三的应用,每月进行整改。新上线应用使用率高,则应大规模推广,使用率低考虑功能是否便利,解决了用户的问题。
这些都是可以通过系统的统计分析出来的,设置分析的规则需要根据具体的业务来。
3.用户画像(分析用户特征)
用户画像则是对用户的一些使用习惯进行分析,常见的方式有贴标签,特长。
比如很多应用注册时会要求用户选择感兴趣的领域。系统也可根据用户的访问内容的标签进行相关联,用户查看过某一新领域后尝试推送该领域的热门内容,如果继续点开,或者点开率达到50%及以上,那么可为该用户推荐该领域的相关内容并打标签。标签的分类可包括手动选择,自动选择。
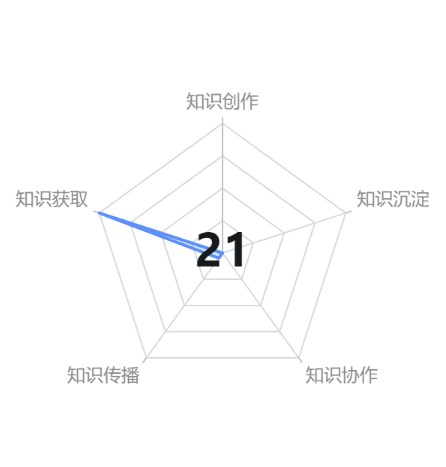
比如在知识领域。定义为五个模块,知识创作,知识获取,知识沉淀,知识传播和知识协作。知识获取可定义为下载、浏览文件、查询文件,知识创作可定义为编辑、上传文件。
知识传播可定义为转发文件,知识协作可定义为共享文档的编辑,知识沉淀可根据用户在线查看文档的时长来定义。不同的维度设置定义的角度,为用户生成画像。
4. 故障预测(时间序列)
根据故障出现的周期性可对故障进行预测。防范于未然。统机器学习方法如何应用于时间序列预测,包括循环神经网络、卷积神经网络、Transformer、自回归模型、状态空间模型、支持向量机和随机森林等。故障的预测优先于故障的处理,减少故障发生的频率。
四、结语
埋点日志的统计维度非常多,统计的内容也很多。本文只是根据作者所在行业的系统做的一些思考。还有很多内容可以进行统计,比如业务办结率,地区贯通率等等。
在设计统计分析内容之前一定要做好前置工作,不然真正做起来的时候各种数据的缺失会让工作前功尽弃。
其次,每个数据项的统计规则一定要定义好,跟开发尽可能多地沟通交流。希望大家能根据自己工作的内容来做统计与分析,欢迎评论区交流想法!